论文信息:NIPS 2016 WorkShop
Project Page::https://github.com/imatge-upc/detection-2016-nipsws
整体框架:提出了一种基于强化学习的层次目标检测方法(Hierarchical Object Detection)。关键点在于: 专注于图像的含有更多信息量的区域, 并且放大该区域. 我们训练一个 intelligent agent, 给定一个图像窗口,能够确定将注意力集中于预先设定的五个区域中的哪一个. 这个过程迭代的提供了一个等级的图像分析. 我们对比了两个不同的候选 proposal 策略来引导图像搜索: With and without overlap. 此外, 我们的方法对比了两种不同的策略来提取特征: 第一种是对每一个 region proposal 计算新的 feature map ; 另一种方法是对于整幅图像计算 feature maps 并为后续的每一个 region proposal 提供 crop 的feature map. 当我们观察图像时,我们总是对信息进行连续的提取,以便理解它的内容。首先,我们将视线固定到图像的最突出部分,从提取的信息中,引导我们朝向另一个图像点,直到我们分析了所有的相关信息。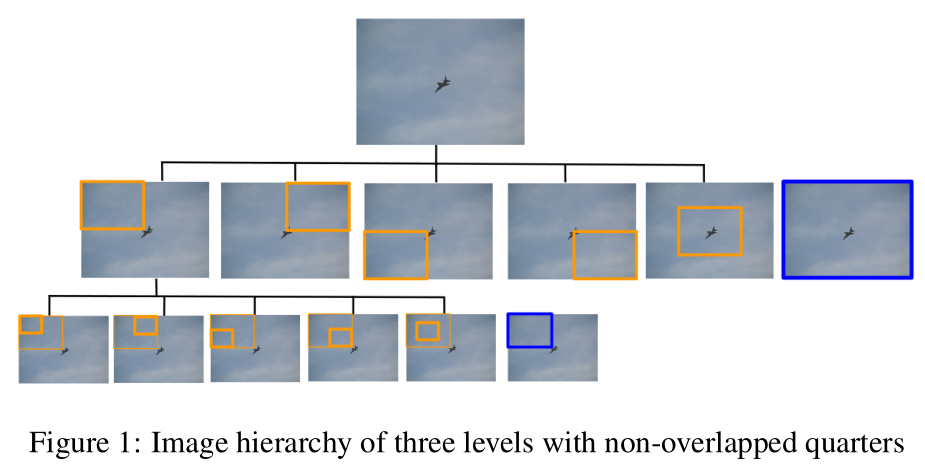
通常目标检测方法都是独立地分析图像区域,区域之间没有任何相关性,通过引入图像的层次表示,就能很容易探索区域之间的关系。文章使用一种top-down 扫描的方式:首先对image进行global view然后依次focus on 具有相关信息的local parts.
作者基于RL设计了一个agent,这个agent首先分析整个image,然后在预先准备好的5个region:four regions representing the four quadrants plus a central region(4个象限区域+1个中心区域)中选择一个。此外应用两种不同的策略来crop region : proposing overlapping or non-overlapping candidates
使用上面的方法就使得object限制于predefined regions中。
贡献:
1)将RL引入到object detection中,并引入hierarchical representation来引导agent寻找目标;
2)使用了两种不同的hierarchical representation;
2)提取每个区域的特征而不是reuse特征(roipooliing 特征)。
模型 Hierarchical Object Detection Model :
作者定义了物体检测问题当做是序列决策过程 (the sequential decision process). 每一个时间步骤, agent 应该决定图像的哪个区域应该集中注意力, 以便于少量的步骤内找到物体. 我们将这个问题看作是 Markov Decision Process , 提供了一个框架来建模 decision making.
MDP formulation :
作者首先定义了 MDP 的大致过程 : state, actions, reward :
state : 当前区域 和 记忆向量 构成, 即: the current region and a memory vector. 描述子定义了两个模型: the Image-Zooms model and the Pool45-Crops model .状态的记忆向量(memory vector)捕获了agent 搜索物体当中,已经选择的过去 4 个 actions. 由于 agent 是学习一个 bounding box 的 refinement procedure, 一个记忆向量编码了这个 refinement procedure 的状态 用来稳定搜索轨迹. 我们将过去的 4 个 actions 编码成一个 one-shot vector. 由于本文定义了 6 个 actions, 所以向量的维度是 24.
Actions : movement actions + terminal action 和ICCV 2015 年的那个检测的方法一样不一样的是,ICCV 2015定义的actions是9个:上下左右移动4个,尺寸放大缩小2个,宽高比例瘦高2个以及终止操作1个, 这里的action 有6个:4个quadrants区域移动+1个center区域移动+1个终止trigger。
Rewards : 此处的设计 与 ICCV 2015是一致的。下面公式(1)表示移动reward函数,(2)终止结束reward函数;


Q-learning函数设计
在增强学习中,通过设计Q(s,a)函数来获得每个state的最佳actions。

Model

作者设计了两种不同的feature extraction。讨论了两种提取特征的方法, 上面就是所用的大致网络框架. Image-Zooms model and the Pool45-Crops model.
对于 Image-Zooms model 来说, 每一个区域都 resize 成 224*224 的大小, 然后抽取 VGG-16 的 Pool 5 layer 的特征.
对于 Pool45-Crops model, 图像是 full-resolution 传给 VGG-16 的 Pool 5 layer.
上面是对每个region进行一次前向操作,提取特征;后者是和faster rcnn 模式一样,只进行一次前向操作,提取roi pooling特征。实验结果表明,前者要比后者的实验效果更好,原因后者的有些目标的region经过1/16,并没有7*7的大小,那么在输入到DQN中时是需要up sampling.
http://www.cnblogs.com/wangxiaocvpr/p/6066044.html
https://www.youtube.com/watch?v=RdjuNpwKQi8


上面是实验结果作者仅对PASCAL_VOC中的一类aero plane进行实验。